
Mohammad Mahdi Abootorabi
MASc in ECE at UBC and Vector Institute


 RAG-based Educational Assistant Chatbot This is an end-to-end educational chatbot using a RAG architecture to provide reliable, country-specific guidance for students. The system features a Vue frontend, a Node.js backend, and a Python FastAPI service that leverages Sentence Transformers for embedding generation. This RAG approach ensures responses from integrated LLMs are grounded in verified documents, have memory, and also fast, effectively minimizing hallucinations. |  Autonomous Vision-Powered Travel Agent This is an autonomous agent that processes natural language queries for travel planning. The agent innovatively navigates any booking website by opening a browser for the user without relying on its underlying HTML structure. It leverages a multimodal approach combining Computer Vision with an LLM to visually interpret screenshots, mimicking human cognition to extract, filter, and present flight options. |  Health Information Retrieval System An advanced search engine designed for efficient retrieval and organization of health and medical-related content. It uses techniques like Boolean search, TF-IDF, FastText, Transformers, and Elasticsearch models. The system features a user-friendly interface and can be deployed on online servers. |
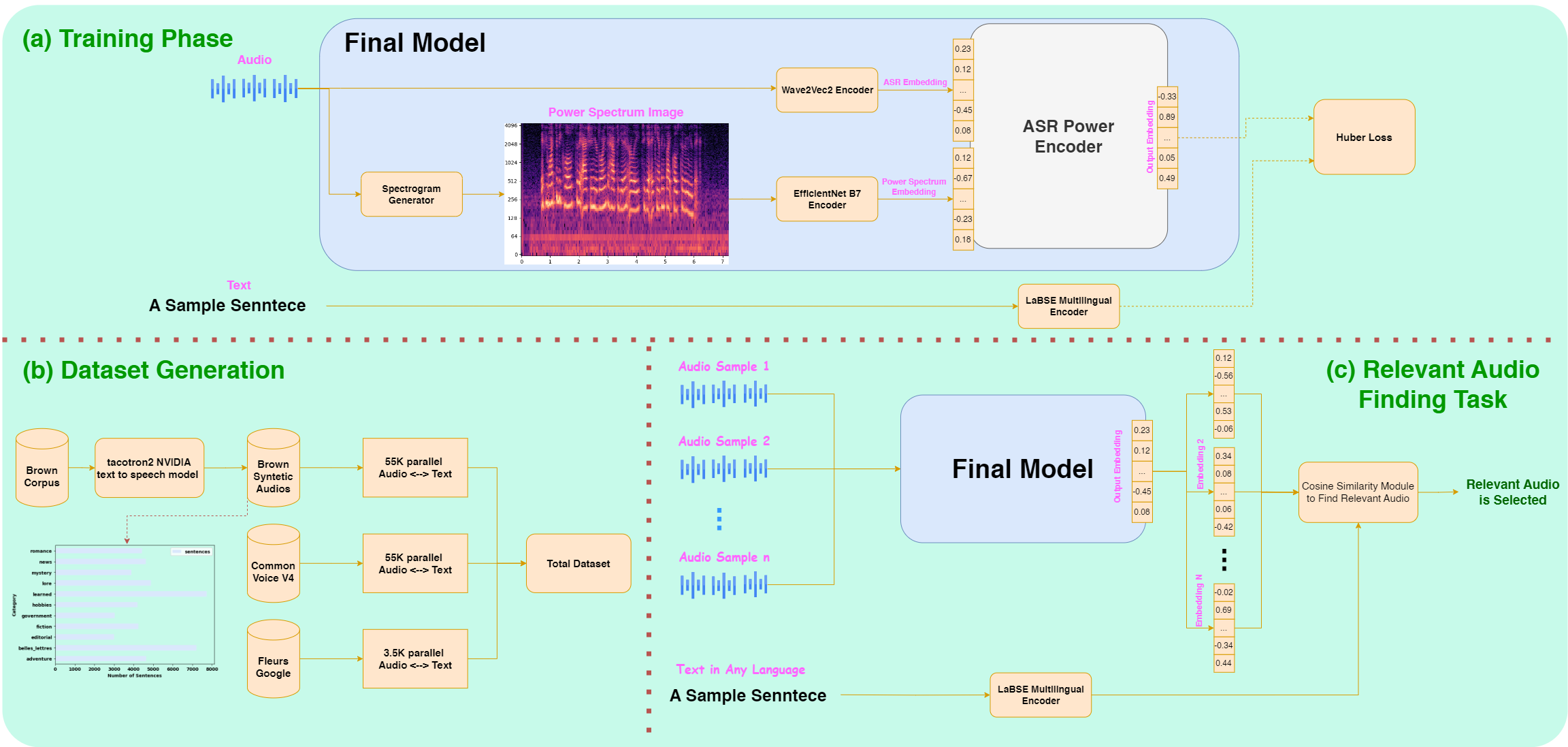 Contrastive Language-Speech Pretraining for Multilingual Multimodal Information Retrieval CLASP is a multilingual, multimodal representation model designed for audio-text information retrieval. It uses contrastive learning to bridge the gap between language and speech domains and is trained on a diverse speech-text dataset. The model sets new benchmarks in retrieval metrics across multiple languages. It created the shared embedding space for speech and text. |  Automated Resume Parser A Python package, designed as an automated resume parser, extracts valuable information from multiple CVs and stores it in a CSV file. Currently supporting Persian CVs, it enhances Applicant Tracking Systems’ review capabilities. |  Bias detection & De‐biasing in Language Models This project focuses on the detection and mitigation of various biases, such as gender and ethnic biases, in diverse language models, including those for multiple languages and multilingual models. A significant aspect of the project is the development of de-biasing techniques specifically tailored for Persian language models. |
 Personal Information Hider A Python package designed to enhance privacy by concealing personal information in text files. It uses POS tagging and regex-based solutions to effectively remove identifiable details like names, addresses, URLs, email addresses, and more. |  Automated Medical Report Generation for Fundus Fluorescein Angiography Images This project presents a new model for automated medical report generation from FFA images. It uses a CNN for visual feature extraction, Cross-modal Memory for feature alignment, and a reinforcement learning algorithm guided by NLG metrics for report generation. |  MemoReminder MemoReminder is a mobile application that allows you to share and relive your best moments. It is available on both iOS and Android platforms. |
 News Classification, Summarization, & QA System This project is a comprehensive system for Persian news analysis, equally focusing on classification, question answering, and summarization. It classifies articles using TF-IDF and transformer models, generates relevant questions and answers, and provides fine-tuned summarization of news content. | 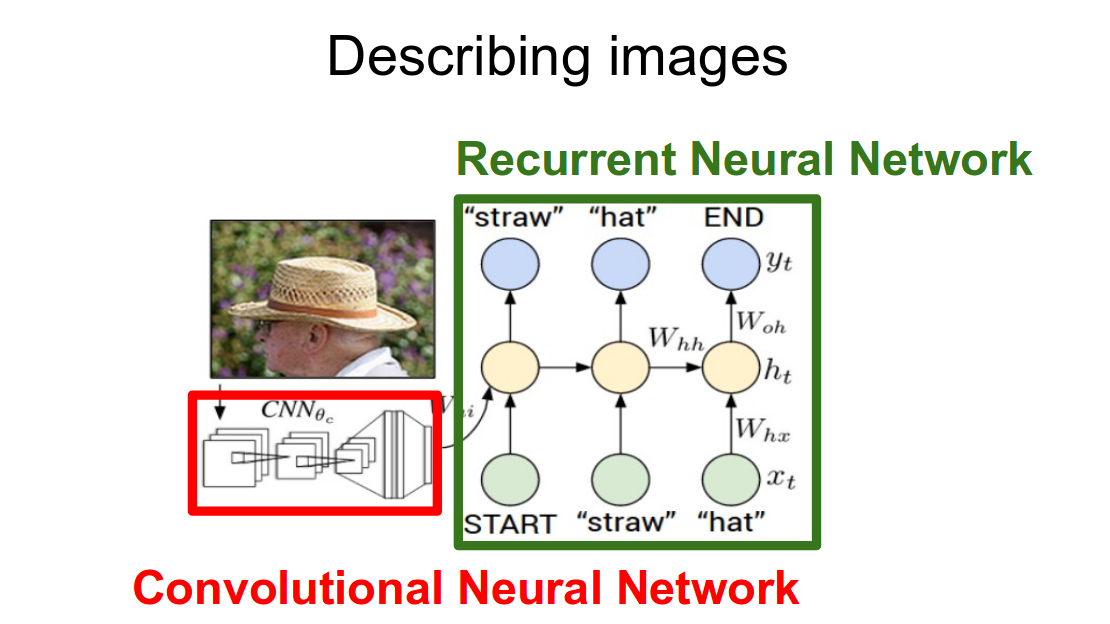 Automated Image Captioning with Recurrent Neural Networks An RNN-based system that generates relevant captions for images. It utilizes pre-trained ResNet50 for image feature extraction and LSTM networks for text generation. |  Neural Network Implementation from Scratch This project involves the development of a neural network from scratch using NumPy, applied to the CIFAR-10 dataset for image classification. |
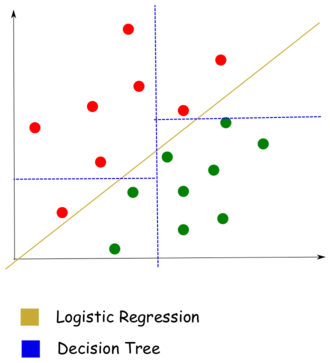 Implementation of Classical Machine Learning Models This project involves the implementation of three classical machine learning models: Linear Regression, Decision Tree, and SVM. The models are trained and evaluated on various datasets, with preprocessing tasks such as PCA and EDA also performed. |  Content Management System This project is a versatile content management system that allows you to create and manage various types of libraries (videos, music, books, pictures) and share them with your friends. |  Text Exploration This project involves the crawling, exploration, and analysis of text from two websites, Zoomg and Skysports, using NLP methods to extract meaningful insights. |
 Drowsiness Detection Embedded System This project is a real-time drowsiness detection system that uses your webcam to monitor signs of drowsiness and phone usage. |